Latest Posts
Population-based outreach to prevent suicide attempts? Now we know.
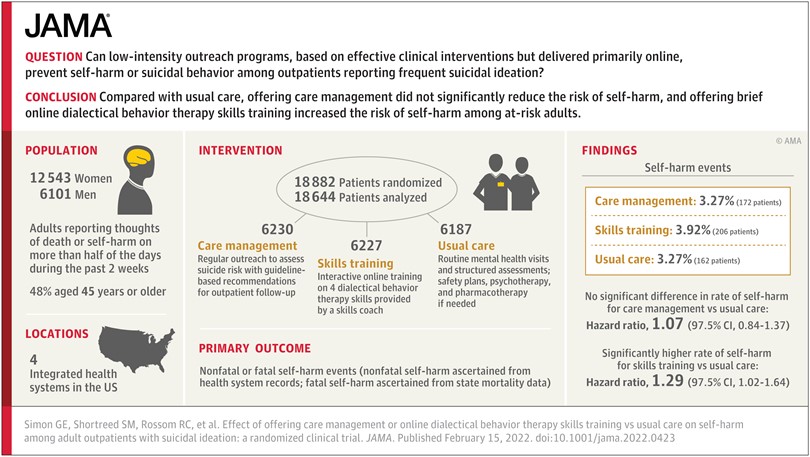
We recently published the results from our large pragmatic trial of outreach programs to prevent suicide attempts.
Can we be passionate and skeptical?

During discussions in grant review panels, I’ve often heard an investigator described as “passionate” about their proposed work. That “passionate” label is usually spoken as praise and endorsement. But that word sometimes worries me.
Come Sit with Me for a While

Over the last two months, I’ve helped at some of KP Washington’s weekend COVID-19 vaccination clinics. After a year of pandemic disruption and worry, giving vaccine shots is really a joy. I’ll definitely remember the day we vaccinated over 1,100 schoolteachers.
The Cautionary Tales of Scott Atlas and Dr. Oz

Three events in the last month got me thinking about the role that clinicians and researchers (like me) play in the popular media.
Did Suicide Deaths Increase or Decrease During the Pandemic? – Another Embarrassing Mistake Avoided

I’ve previously written that healthcare research needs a Journal of Silly Mistakes We Almost Made. Until that journal is established, I’ll have to share my examples with readers of this blog. It’s a small audience, but I like to think it’s a discerning one.
Noticing My Tailwind
One of my favorite Seattle bike rides goes south along the shore of Lake Washington to Seward Park and then back north to Capitol Hill. That route was especially pleasant during the past summer when Lake Washington Boulevard was temporarily closed to cars.
Looking for Equipoise
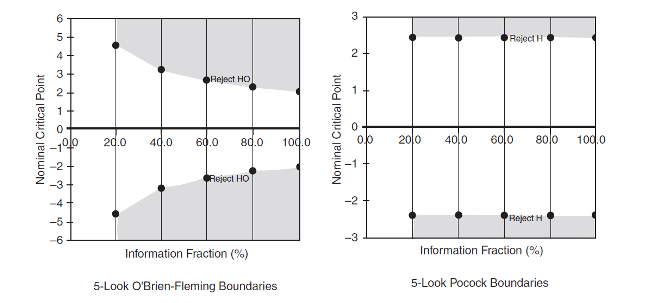
Controversy regarding potential treatments and vaccines for COVID-19 has brought arguments about randomized trial methods into the public square. Disagreements about interim analyses and early stopping of vaccine trials have moved from the methods sections of medical journals to the editorial section of the Wall Street Journal. I never imagined a rowdy public debate about the more sensitive Pocock stopping rule versus the more patient O’Brien-Fleming rule. A randomized trial nerd like me should be heartened that anyone even cares about the difference. I imagine it’s how Canadians feel during Winter Olympic years when the rest of the world actually watches curling. But the debates have grown so heated that choice of a statistical stopping rule has become a test of political allegiance. And that drove me to some historical reading about the concept of equipoise.
Judging Which (mathematical) Model Performs Best: Is it More than a Fashion Show?

Projections of the course of the COVID-19 pandemic prompted vigorous arguments about which disease model performed the best. As competing models delivered divergent predictions of morbidity and mortality, arguments in the epidemiology and medical twitterverse grew as rowdy as the crowd in that male model walk-off from the movie Zoolander. Given the rowdy disagreement among experts, how can we evaluate the accuracy of competing models yielding divergent predictions? With all respect to the memory of David Bowie (the judge of that movie modeling competition), isn’t there some objective way of judging model performance? I think that question leads to a key distinction between types of mathematical models.
Incredible Research is Sometimes Not Credible

The controversy around COVID-19 research from the Surgisphere database certainly got my attention. Not because I have any expertise regarding treatments for COVID-19, but because I wondered how that controversy would affect trust in research like ours using “big data” from health records.
Delivering on the Real Promise of Virtual Mental Healthcare

Many of our MHRN investigators were early boosters of telehealth and virtual mental health care. Beginning over 20 years ago, research in our health systems demonstrated the effectiveness and value of telehealth follow-up care for depression and bipolar disorder, telephone cognitive-behavioral or behavioral activation psychotherapy, depression follow-up by online messaging, online peer support for people with bipolar disorder, and telephone or email support for online mindfulness-based psychotherapy.
Pragmatic trials for common clinical questions: Now more than ever

Adrian Hernandez, Rich Platt, and I recently published a Perspective in New England Journal of Medicine about the pressing need for pragmatic clinical trials to answer common clinical questions. But the need for high-quality evidence to address common clinical decisions is now more urgent than we could have imagined.
“H1-H0, H1-H0” is a song we seldom hear in the real world

Arne Beck and I were recently revising the description of one of our Mental Health Research Network projects. We really tried to use the traditional scientific format, specifying H1 (our hypothesis) and H0 (the null hypothesis). But our research just didn’t fit into that mold.
Read Marsha Linehan’s book!

If the Mental Health Research Network had a book club, we’d start with Marsha Linehan’s memoir, Building a Life Worth Living.
Let’s not join the Chickens**t Club!

Long before he became famous or infamous (depending on your politics) as FBI Director, James Comey served as US Attorney for the Southern District of New York. That’s the office responsible for prosecuting most major financial crimes in the US. Jesse Eisinger’s book, The Chickens**t Club, recounts a speech Comey made to his staff after assuming that high-profile post. He asked which of his prosecutors had never lost a case at trial, and many proudly raised their hands. Comey then said, “You are all members of what we like to call The Chickens**t Club.” By that he meant: You are too timid to take a case to trial unless you already know you will win.
From 17 years to 17 months (or maybe 14)
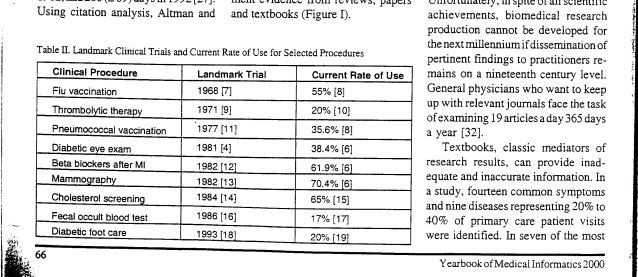
Most papers and presentations about improving the quality of health care begin by lamenting the apocryphal 17-year delay from research to implementation. The original evidence for that much-repeated 17-year statistic is pretty thin: a single table published in a relatively obscure journal. But the 17-year statistic is frequently cited because it quantifies a widely recognized problem. Long delays in the implementation of research evidence are the norm throughout health care.
Outreach is Meant for the People Left Outside!

Several years ago, Evette Ludman and I undertook a focus group study to learn about early dropout from psychotherapy. We invited health system members who had attended a first therapy visit for depression and then did not return. Only about one-third of people we invited agreed to speak with us, but that’s a pretty good success rate for focus group recruitment.
Marianne Williamson vs. the DSM-5

Psychiatric epidemiology has become a Presidential campaign issue! Marianne Williamson has taken some heat for her past claim that diagnosis of clinical depression is “such a scam.” She has backed away from that statement, but she’s stood by her point that “There is a normal spectrum of human despair; it is a spiritual, not a medical issue.” And she’s stood by her claim that antidepressants are over-prescribed when “people are simply sad.” Is there really any difference between depression and ordinary sadness? Are antidepressants being prescribed inappropriately for “normal human despair”?
Who Decides when Science is Junk?

During the last month, I found myself in several conversations about promoting open science. We hope that sharing data, research methods, and early results will make research more rigorous and reproducible. But those conversations all turned to the fear that data or preliminary results could be misinterpreted or even deliberately misused. How can we protect the public from misleading “junk science”?
Who Owns the Future of Suicide Risk Prediction?

On my plane rides to and from a recent meeting about big data in suicide prevention, I finally read Jaron Lanier’s 2013 book Who Owns the Future? If you’ve read it -or read much about it – you can skip the rest of this paragraph. Lanier is a legendary computer scientist often cited as the creator of virtual reality. The first half of his book (my eastbound reading) is a Jeremiad about the modern information economy de-valuing human work and hollowing out the middle class. Jobs are disappearing, income inequality is increasing, and personal information is devoured and monetized by big tech companies. While Lanier gives a free pass to scientific users of big data, I think some of his criticisms still apply to our work. The second half of the book (my westbound reading) proposes a solution. It’s a new economic model rather than a new regulatory structure. Lanier argues that those who create useful information should be paid by those who profit from it. If you discover a secret shortcut around rush-hour traffic, then Google Maps may route other people to follow you. Your shortcut might be ruined tomorrow, but your bank account would show a micro-payment from Google for “selling” your discovery to other drivers. If you are an expert discoverer of efficient driving routes (like my wife), then Google might pay you over and over for the valuable driving data you create.
Are the Kids Really Alright?

If you’re my age, “The Kids Are Alright” names a song by The Who from their 1966 debut album, My Generation. If you’re a generation younger, it names a movie from 2010. If you’re even younger, it names a TV series that debuted just last year. What goes around comes around – especially our worry that the kids are not alright.
Bebe Rexha can Call Herself Whatever She Wants

“I’m bipolar and I’m not ashamed anymore. That is all. (crying my eyes out.)”.)
— Bebe Rexha (@BebeRexha) April 15, 2019
I cheered about a talented and successful woman announcing that she is not ashamed to live with bipolar disorder. But I initially paused when reading the words “I’m bipolar.” That’s the sort of language that many mental health advocates discourage. I’ve been trying to unlearn language like that.
Is it Too Soon to Move the Tomato Plants Outside?

It’s the time of year when backyard gardeners start to think about transplanting tomato seedlings from that tray in the sunny part of the kitchen to the real garden outside. Moving outdoors too soon is risky. Those little seedlings could get beaten down by the cold rain, nibbled by the escaped Easter bunnies running wild in my neighborhood, or decimated by cutworms. Gardeners in the Northeast and Midwest even need to worry about late-season snow. But you don’t want to wait too long, or you’ll end up with root-bound, leggy plants and a disappointing tomato crop.
Isn’t Prediction About the Future?

This post will be a nerdy one. I want to split some hairs about use of the word “predict”. But I think they are hairs worth splitting.
Friction Won’t Stop Us Anymore!

Seattle had one of its rare snowy days last week. Seeing cars slide sideways down our hills reminded me that friction is sometimes our friend.
Have We Become Helicopter Researchers?

“Helicopter Parents” is the derisive term for those over-protective parents who won’t let their children experience any failure – or even any actual challenge. The helicopter critique is supported by anecdotes of parents overly involved in children’s homework or parents intervening too vigorously when children have disappointing experiences in school or sports. “Participation Trophies” given to every member of a sports team are held up for special ridicule.
Return of the Repressed

Last month I moved to a temporary office to make way for painting and installing new carpet. Being forced to pack up every book and file folder was actually a good thing. I recycled stacks and stacks of paper journals. Saving those was a habit left over from the last century. I cleaned out file drawers full of old paper grant proposals and IRB applications, relics from the days before electronic submission. I purged stacks and stacks of paper reprints (remember those?) from the 1990s. I recycled books I hadn’t opened in 15 years. Tidying up did feel good, but my purging frenzy paused when I came to this stack of books from my residency days.
Machine learning and Clever Hans, the Calculating Horse

Clever Hans, the Calculating Horse, was a sensation of the early 1900s. He appeared to be able to count, spell, and solve math problems – including fractions! Only after careful investigation did everyone learn that Hans was just responding to unconscious nonverbal cues from his trainer. Hans couldn’t actually calculate, but he could sense the answer his trainer was hoping for.
Gold Standard or Golden Calf?

Most of our measures and measurement tools were created in conference rooms or conference calls dominated by older white men – like me, I guess. Over time, those “expert opinion” measures acquire a patina of authority. As time passes, we can start to equate familiarity or habit with accuracy or validity. Like the biblical story about worshipping a false idol that we created ourselves, we start to see a gold standard rather than just a statue of a golden calf.
What’s so Funny About Dimensionality Reduction?
My wife handed me a recent issue of The New Yorker and recommended the Shouts and Murmurs column. It parodied a whistle-blowing data scientist testifying before Parliament about modern analytic methods. He grows increasingly frustrated as legislators can’t follow his explanations of eigenvectors and dimensionality reduction.
Can you see me now?

As our health systems prepare to implement statistical models predicting risk of suicidal behavior, we’ve certainly heard concerns about how that information could be misused. Well-intentioned outreach programs could stray into being intrusive or even coercive. Information about risk of self-harm or overdose could be misused in decisions about employment or life insurance coverage. But some concerns about predictions from health records are unrelated to specific consequences like inappropriate disclosure or intrusive outreach.
MHRN Blog World Cup Edition: What Soccer Referees Know about Causal Inference

When Nico Lodeiro falls down in the penalty area, I hold my breath waiting for the referee’s call. Was it really a foul – or just Nico simulating a foul? The stakes are high. If the referee calls it a foul, it’s a penalty kick and likely goal for my Seattle Sounders. If she calls it a simulation or a dive, then it’s a yellow card warning for Nico. After the call, we all watch the slow-motion replay. I used to be surprised at how often the refs got it right until a referee friend of mine explained what the refs are looking for.
Suicide Risk Prediction Models: I Like the Warning Light, but I’ll Keep My Hands on the Wheel

Our recent paper about predicting risk of suicidal behavior following mental health visits prompted questions from clinicians and health system leaders regarding practical utility of risk predictions. Our clinical partners asked, “Are machine learning algorithms accurate enough to replace clinicians’ judgment?” My answer was, “No, but they are accurate enough to direct clinicians’ attention.”
Why I’ll Join the All of Us Research Program

NIH’s All of Us Research Program officially launched on Sunday, May 6th. It’s an ambitious national effort to bring together at least one million people from across the U.S. in a long-term study of health across the lifespan. All of Us is not just a biobank or a genetic study. It’s a 360-degree view of health and disease, with just as much attention to environment as genetics and just as much attention to resilience as to vulnerability.
Advice To Young Researchers: Don’t Find Your Niche

University-based researchers often contact our network, hoping to do research in our health systems to evaluate new interventions or programs. Those new interventions or programs are usually specific adaptations of treatments already proven to work. Typical examples (slightly anonymized) include: a care management program for people with depression and rheumatoid arthritis, a mobile health intervention teaching mindfulness skills after psychiatric hospital discharge, or a training program to help clinicians provide structured psychotherapy specific to bereavement.
When does caring cross over into creepy?

A recent news article about the European Union’s new privacy rules prompted me to think more about population-based suicide prevention programs. Caring outreach that respects privacy is a difficult balance.
Alexa, should I increase my dose of Celexa?

The evolution of depression care management programs can be described in terms of task shifting. Initial Collaborative Care programs actually shifted some tasks up to specialty providers. Psychiatrists and psychologists joined the primary care team and assumed responsibility for routine follow-up of antidepressant treatment.
There might be no fish. But again, well, there might!

In the MHRN Suicide Prevention Outreach Trial, our coaches patiently and persistently reach out to people at risk for suicide attempt. Coaching messages offer support and encouragement, with specific reminders to use our online program teaching skills for emotion regulation.
But My Patients Really Are More Difficult!

Comparisons of the quality or outcomes of care across providers or facilities often meet the objection: “But my patients really are more difficult!” If we hope to improve the quality and outcomes of mental health care, we must address that concern. However, that automatic objection shouldn’t invalidate comparisons or excuse all variations. Instead, it should prompt careful thinking.
Do You Believe An Algorithm Or Your Own Lying Eyes?

Our work on machine learning to predict suicide attempts and suicide deaths is moving rapidly to implementation. Among mental health specialty visits, we are now able to accurately identify the 5% of patients with a 5% likelihood of a treated suicide attempt in the following 90 days. Our health system partners believe those predictions are accurate enough to be actionable.
Are we river pilots or rent-seekers?

The bar at the mouth of the Columbia River creates a uniquely dangerous entrance to a major shipping route. Rapidly changing conditions there have sunk over 2000 large ships in the last 200 years. Local knowledge is essential to crossing the bar safely. Turn-by-turn directions from your phone are just no help there, especially when the seas are rough. As a freighter approaches from the Pacific, a Columbia River Bar Pilot comes on board to navigate through the ten-mile danger zone. The picture above shows a Columbia Bar pilot arriving by boat to take over the helm.
That’s Like Getting Struck by Lightning!
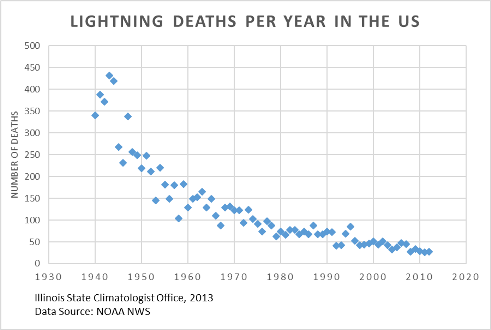
I am a converted skeptic regarding population-based suicide prevention. Until about 5 years ago, I would have argued that we lacked the two essential ingredients for effective prevention: accurate tools to identify people at risk and practical interventions to reduce that risk. I might have even said, “That’s like getting struck by lightning! How can you predict that? Even if you could predict it, what could you do to change the weather?” It turns out that suicide prevention may actually be similar to preventing death by lightning strike – just not in the way I was expecting.
Can Health Services Defeat Epidemiology?
Can health services defeat epidemiology? This question is not inspired by the School of Public Health summer softball league. Instead, it’s inspired by a conversation with my colleague Ed Boudreaux about screening for suicidal ideation as a tool for preventing suicide attempts and suicide deaths.
Social Determinants of Health: What’s in a Name?

I have a beef with the name “Social Determinants of Health”.
Who decides what a word means?

Our collaboration with MHRN health systems to improve depression care has emphasized the systematic use of standard outcome measures – like the PHQ9 depression scale. More recently, we have encouraged use of the 9th item of the PHQ9 (regarding thoughts of death or self-harm) as a tool for identifying people at risk for suicidal behavior. Front-line clinicians and health system managers often ask whether those standard questionnaires can accurately measure depression or predict suicidal behavior across diverse patient populations.
Coordinated Care for First-Episode Psychosis and the End of Gadgets

As MHRN investigators, we often hear from academic researchers hoping to study new psychotherapies or eHealth interventions in our healthcare systems. Those new interventions typically focus on a specific diagnosis (like obsessive-compulsive disorder) or patient subgroup (like depression in people with arthritis). But when we bring these ideas to leaders in our care delivery systems, their interest in these specific interventions is often low. Our health system partners are typically more interested in broader care improvements – like measurement-based care for depression or addressing suicide risk across all diagnoses.